MotionLLM: Understanding Human Behaviors from Human Motions and Videos
Ling-Hao Chen😎 1, 3,
Shunlin Lu😎 2,
3,
Ailing Zeng3,
Hao Zhang3, 4,
Benyou Wang2,
Ruimao Zhang2,
Lei Zhang🤗 3
😎Co-first author. Listing order is random.
🤗Corresponding author.
1Tsinghua University
2School of Data Science, Shenzhen Research Institute of Big Data, CUHK (SZ)
3International Digital Economy Academy (IDEA)
4The Hong Kong University of Science and Technology

📖 Abstract
This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs). Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively. In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights. Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion. Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.🤩 Introducing MotionLLM
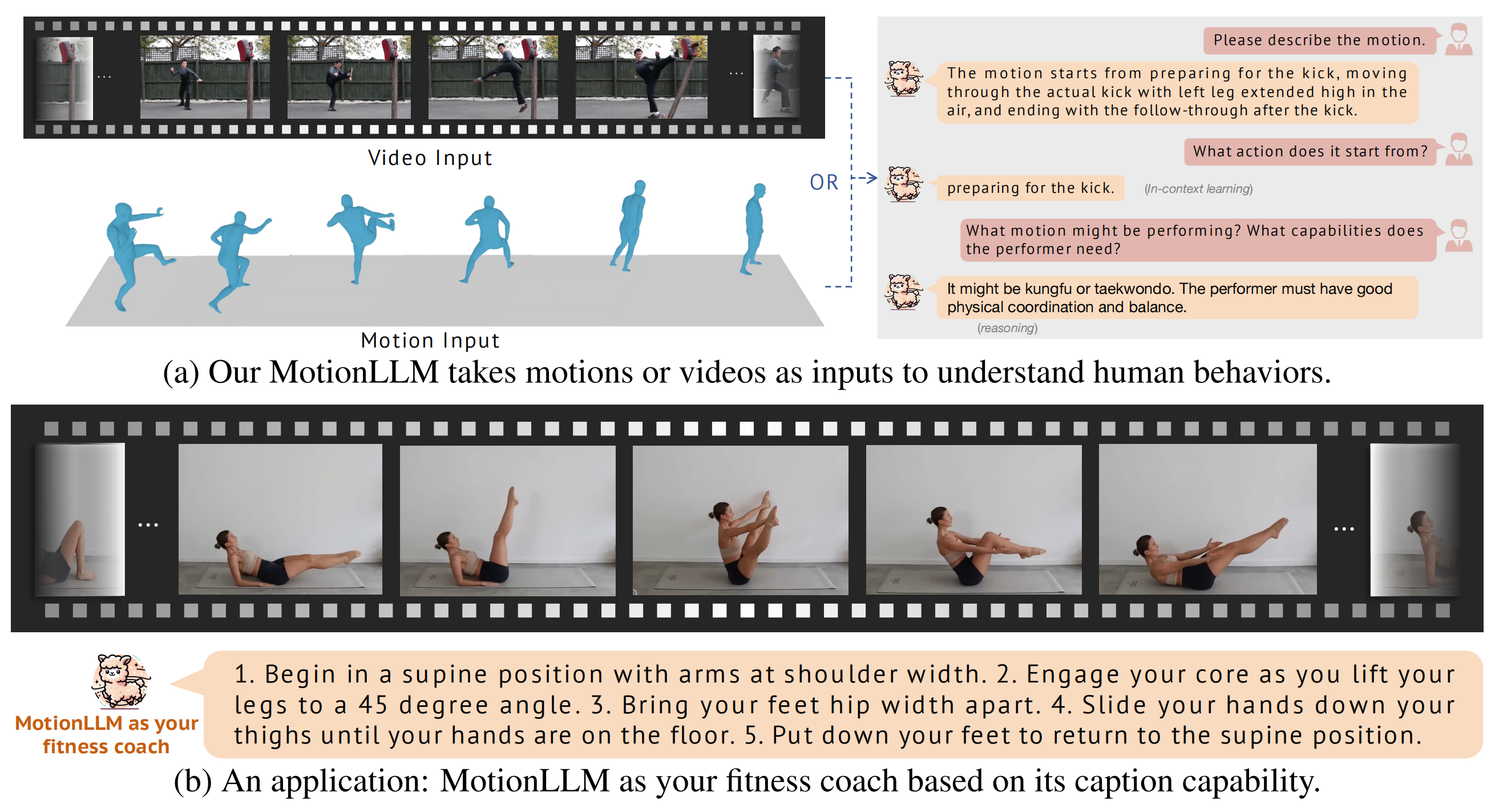
Introducing MotionLLM. (a) The input and output of MotionLLM. (b) MotionLLM has broad application scenarios, such as an intelligent fitness coach.
🤩 Interesting Results
✌️ More Features
🤝 Motion and Video Data Help with each other!
🤗 Live Demo
👀 System Overview
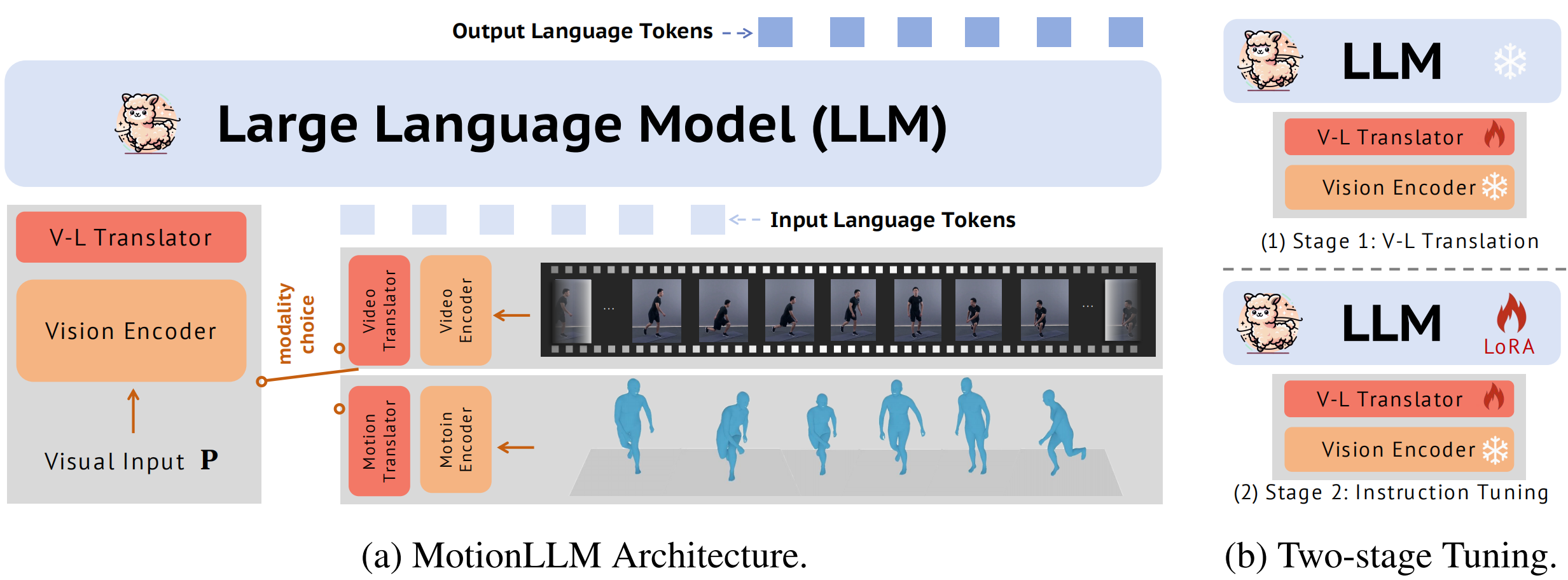
System overview of MotionLLM. (a) MotionLLM takes videos or human motions as visual input V. It first processes the visual input with a vision encoder and translates the vision embeddings into linguistic space via a V-L translator. (b) MotionLLM is trained in two stages. In the first stage, we train the V-L translator to learn the modality translation. In the second stage, we fine-tune the LLM and the V-L translator via instruction tuning data.
🦾 Technical Detail Comparison
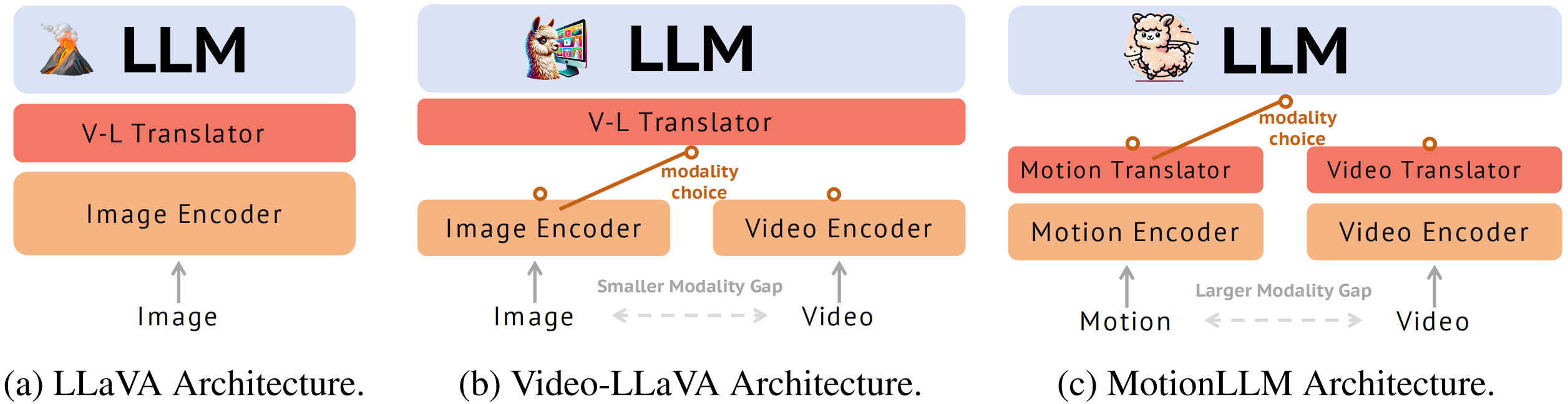
Technical comparisons with other VLLMs. (a) LLaVA takes the images as input only. (b) Video-LLaVA shares a unified V-L translator for images and videos due to the small modality gap between the two modalities. (c) To bridge the larger modality gap between motion and videos, we take two separated V-L translators for better modality translations.
🫡 Comparison with Video Understanding Baselines

Videos comprehension of models.
The results show good performance of MotionLLM on captioning, spatial-temporal comprehension, and reasoning.
The comparison with Video-Chat and Video-LLaVA shows good sequentiality and direction comprehension of MotionLLM.
(* Actor in the video: Shunlin Lu)
💪 Comparison with Motion Captioning Baselines

Examples of motions comprehension. The results demonstrate the proficiency of MotionLLM in captioning, spatial-temporal understanding, and reasoning. Comparison with TM2T and MotionGPT underscores the effectiveness of MotionLLM in handling unseen motions.
🌹 Acknowledgement
Citation
@article{motionllm,
title={MotionLLM: Understanding Human Behaviors from Human Motions and Videos},
author={Chen, Ling-Hao and Lu, Shunlin and Zeng, Ailing and Zhang, Hao and Wang, Benyou and Zhang, Ruimao and Zhang, Lei},
journal={arxiv:2405.20340},
year={2024}
}The website template was adapted from HumanMAC Project.