Skeleton-free, training-free motion transfer
This work explores motion transfer from one video to another, a problem that is crucial for animating diverse characters. Prior work largely focuses on humans or human-like characters and relies on a predefined skeleton, which limits generalization to different species and restricts large-scale training due to the scarcity of labeled cross-topology data. We step out of the skeleton-based framework and propose Motion4Motion, a training-free motion transfer framework that models the motion flow of a subject in a video instead of its skeleton, making motion transfer across species straightforward. Extensive experiments and novel applications show Motion4Motion outperforms strong baselines.
Watch the 2-minute overview
A walkthrough of Motion4Motion, including cross-species transfer and the surprising case of teaching a table how to walk.
Project video — YouTube
Why skeleton-free?
Mainstream motion transfer uses skeletons to bridge the gap between a source and a target character. This works well for human-to-human, but breaks as soon as the morphologies diverge—there is no shared skeletal template between a human, a goose, and a panda, and labeled cross-topology data is scarce. Spatial alignment becomes ill-defined, and existing systems often collapse into stiff movement, identity drift, or sliding artifacts.
Motion4Motion throws away the skeleton. Instead of kinematics, it operates on dense pixel-level motion flow and injects that flow into a pre-trained video diffusion transformer through a simple mechanism we call TransPE—Transferring Positional Encoding.

Motion flow in, motion flow out
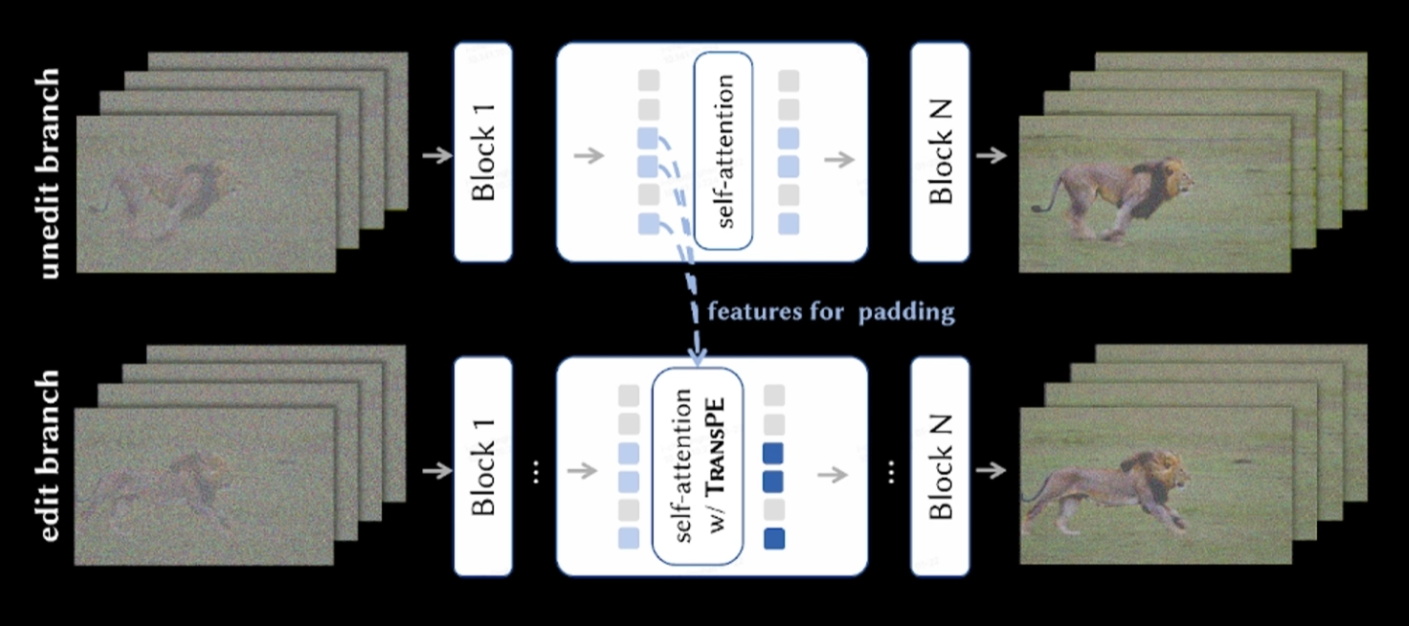
At its core, Motion4Motion is a two-stage inference procedure on top of a frozen Diffusion Transformer (WAN-T2V). We extract a motion flow from the source video, retarget it to the target subject, and then reshape the self-attention of the denoiser so the target appearance follows that flow.
1Motion flow extraction
From the first source frame, we sample anchor points on the subject using Grounded SAM-2. A semantic matcher built on diffusion features establishes cross-image correspondence to the target, while a point tracker yields the temporal trajectories of the source anchors across frames.
2TransPE attention
During denoising, we cache the target subject's K/V, replicate them along time, and re-embed them with RoPE positions taken from the retargeted motion flow. Concatenating these position-aware features into the attention forces the DiT to synthesize the target at the coordinates dictated by the source flow—no training required.
Source motion flow, visualized
The motion flow is a topology-agnostic representation of dynamics: a set of spatio-temporal trajectories that we later read through positional encoding rather than render directly. Below, anchor points tracked across the source video.
Point tracking on the source video.
How K and V are rewired
Given the cached target K/V from inversion, TransPE replicates them along the time axis and re-embeds them with positional encodings taken from the target motion flow. The DiT's query then "looks for" the target's appearance at the new coordinates.
Illustrating the Q/K/V manipulation performed by TransPE.
Cross-species results
On benchmarks for animal (33 pairs) and human (123 pairs) motion transfer, Motion4Motion ranks best across Textual Similarity, Motion Fidelity, Temporal Consistency, Appearance Consistency, and Pose Similarity, outperforming FlexiAct, MotionClone, MotionDirector, RoPECraft, Diffusion-As-Shader, and WAN-Move.
Cross-species motion transfer across different animal pairs.
More cross-species transfers.
Teaching a table to walk
T2V models struggle with novel concept composition like "a desk coming to life, running rapidly along a muddy riverside"—they tend to produce a static or sliding desk. Using Motion4Motion with a light "bone-binding" trick (SAM-2 masks link the human legs to the table legs), we drive a table's gait from a walking human, entirely via flow-based attention manipulation.
Driving a still table with a walking human.

BibTeX
@inproceedings{chen2026motion4motion,
title = {Motion4Motion: Motion Transfer Across Subjects at Inference},
author = {Chen, Ling-Hao and Yin, Zixin and Wang, Duomin and Zeng, Xianfang and Yu, Gang},
booktitle = {SIGGRAPH Conference Papers '26},
year = {2026},
publisher = {ACM},
doi = {10.1145/3799902.3811062}
}