 HumanTOMATO: Text-aligned Whole-body Motion Generation
HumanTOMATO: Text-aligned Whole-body Motion Generation
Shunlin Lu🍅 2,
3,
Ling-Hao Chen🍅 1, 2,
Ailing Zeng2,
Jing Lin1, 2,
Ruimao Zhang3,
Lei Zhang2,
and
Heung-Yeung Shum1, 2
🍅Co-first author. Listing order is random.
1Tsinghua University, 2International Digital Economy Academy (IDEA),
3School of Data Science, Shenzhen Research Institute of Big Data, CUHK (SZ)

Abstract
This work targets a novel text-driven whole-body motion generation task, which takes a given textual description as input and aims at generating high-quality, diverse, and coherent facial expressions, hand gestures, and body motions simultaneously. Previous works on text-driven motion generation tasks mainly have two limitations: they ignore the key role of fine-grained hand and face controlling in vivid whole-body motion generation, and lack a good alignment between text and motion. To address such limitations, we propose a Text-aligned whOle-body Motion generATiOn framework, named HumanTOMATO, which is the first attempt to our knowledge towards applicable holistic motion generation in this research area. To tackle this challenging task, our solution includes two key designs: (1) a Holistic Hierarchical VQ-VAE (aka H²VQ) and a Hierarchical-GPT for fine-grained body and hand motion reconstruction and generation with two structured codebooks; and (2) a pre-trained text-motion-alignment model to help generated motion align with the input textual description explicitly. Comprehensive experiments verify that our model has significant advantages in both the quality of generated motions and their alignment with text.Demo Video
Highlight Whole-body Motions
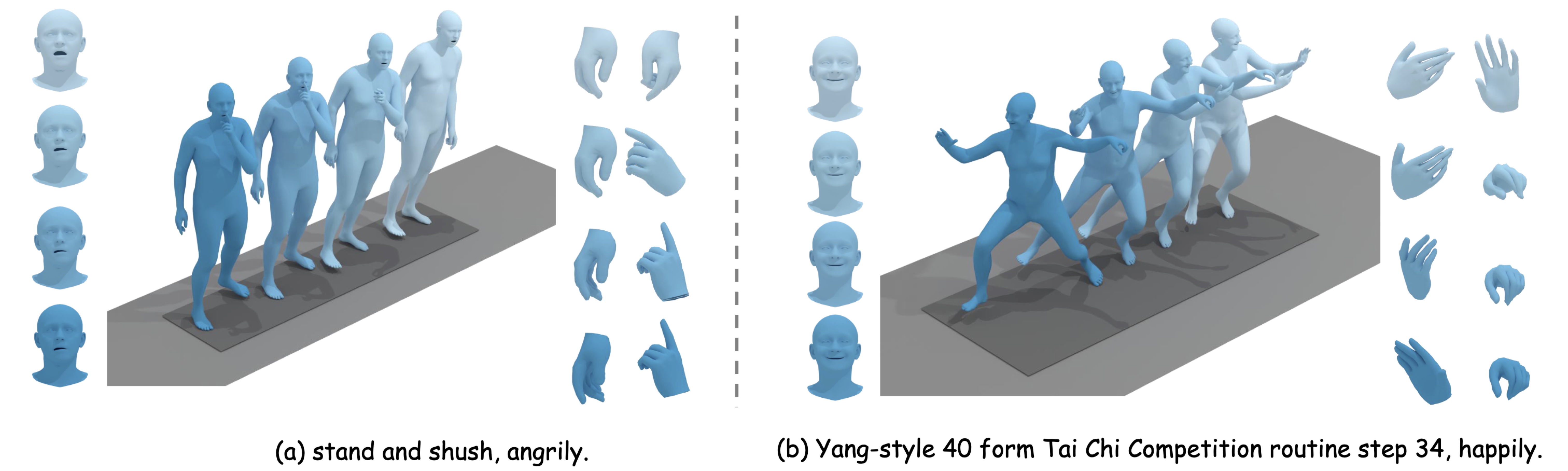
The proposed HumanTOMATO model can generate text-aligned whole-body motions with vivid and harmonious face, hand, and body motion. We show two generated qualitative results.
System Overview
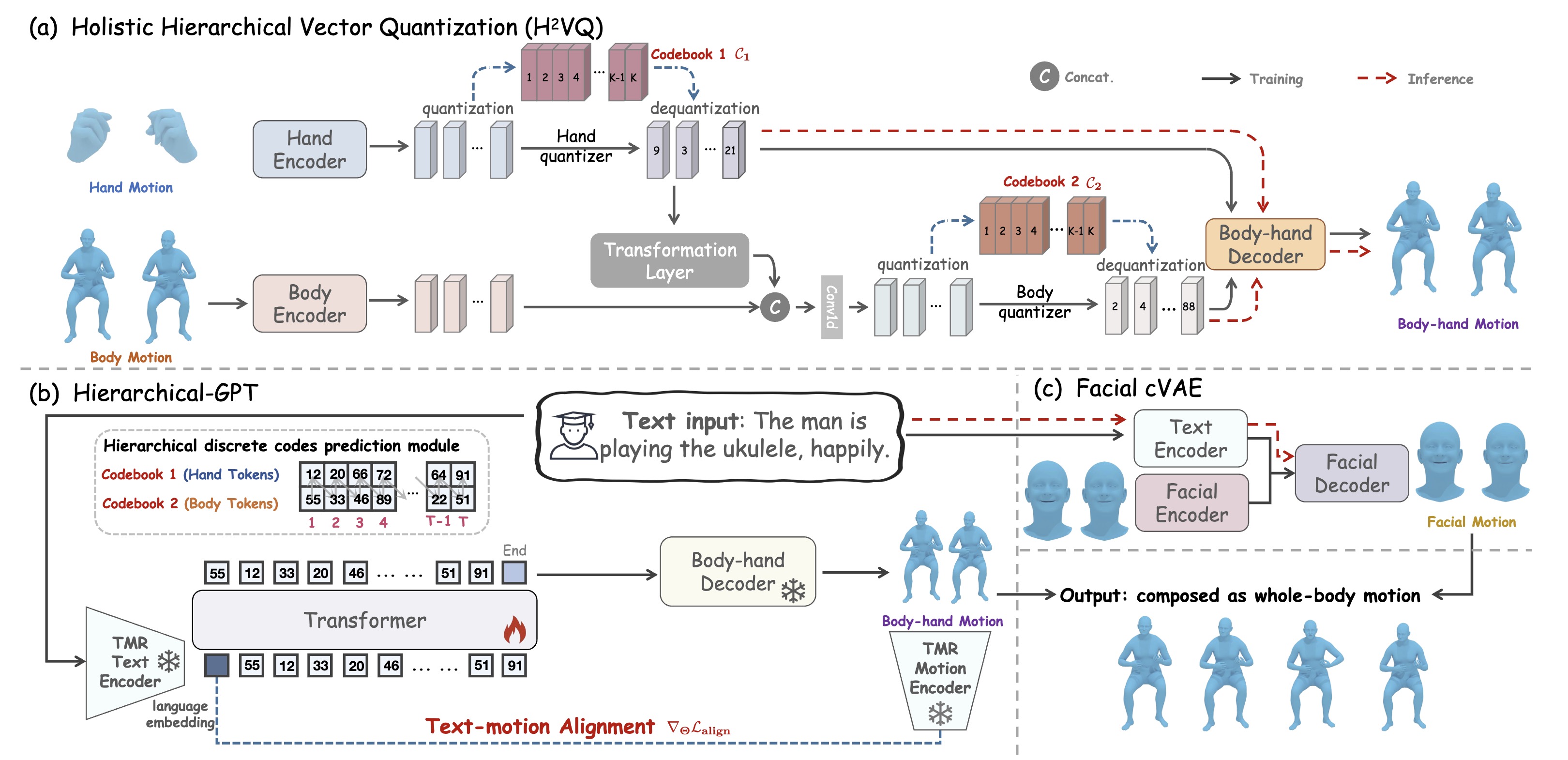
The framework overview of the proposed text-driven whole-body motion generation. (a) Holistic Hierarchical Vector Quantization (H²VQ) to compress fine-grained body-hand motion into two discrete codebooks with hierarchical structure relations. (b) Hierarchical-GPT using motion-aware textual embedding as the input to hierarchically generate body-hand motions. (c) Facial text-conditional VAE (cVAE) to generate the corresponding facial motions. The outputs of body, hand, and face motions comprise a vivid and text-aligned whole-body motion.
Comparing with GT


man swivels left to right with left hand up towards the face.
We found that the generated results of HumanTOMATO were even more vivid than GT. When scratching his face, the man even stretch out his index finger.
Comparing with Baselines


a person walks forward and then backwards.


a person crouches low like a gorilla and walks on all fours from left to right.
We compare the generation result of HumanTOMATO with baselines. Our model has obvious advantages in trajectory, sequentiality and motion rationality.
How does Motion-aware language prior help the motion generation?




To explore how TMR helps the motion generation, we perform our ablation on the Motion-X dataset first. Results show that motion-aware language prior can understand the motion dynamic clues better on sequentiality, directions, and dynamics. Our method helps the text-motion alignment on whole-body motion generation.






Additionally, our Motion-aware language prior also benefits the body-only motion generation. We take the T2M-GPT as a baseline and perform ablation on the HumanML3D dataset. The T2M-GPT model with Motion-aware language prior is shown on the right side. Results show that our method also helps the text-motion alignment on body-only motion generation.
Examples of Motion Reconstruction












Citation
@article{humantomato,
title={HumanTOMATO: Text-aligned Whole-body Motion Generation},
author={Lu, Shunlin and Chen, Ling-Hao and Zeng, Ailing and Lin, Jing and Zhang, Ruimao and Zhang, Lei and Shum, Heung-Yeung},
journal={arxiv:2310.12978},
year={2023}
}The website template was adapted from HumanMAC Project.